一、简介
全称 Redis-REmote DIctionary Server
高性能key-value数据库
内存数据库,支持数据持久化
二、下载安装
这里下载Linux版本的,也有Windows版本的,但不是官方的,由微软维护
# 下载
curl http://download.redis.io/releases/redis-4.0.11.tar.gz -o /tmp/redis-4.0.11.tar.gz
# 解压
tar -zxvf redis-4.0.11.tar.gz
# 进入解压目录编译并安装,编译需要gcc,不指定路径默认为/usr/local/bin/
yum install gcc
cd redis-4.0.11
make PREFIX=/usr/local/redis install
# 安装后,要手动从解压路径拷贝配置文件到安装路径
# 测试是否编译成功(测试需安装tcl)
yum install tcl
make test
编译成功,可执行文件在指定目录下
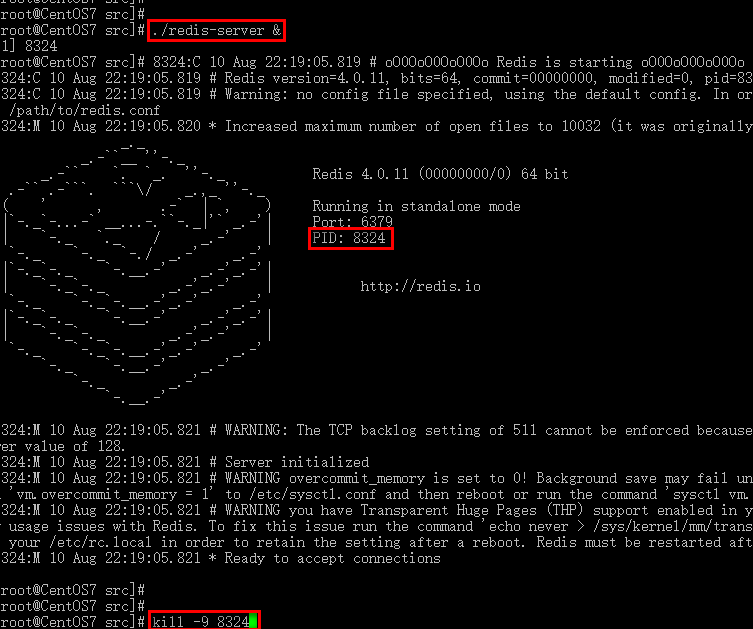
# 启动服务,加上&为后台运行,不占用命令行
./redis-server &
# 指定配置文件方式启动
./redis-server ${redis.conf}
# 指定端口号启动
./redis-server --port 端口号
# 强制停止服务
kill -9 PID进程号
# 停止服务
./redis-cli -p 端口号 -h 地址 shutdown
# 启动客户端
./redis-cli
# 指定参数启动客户端
./redis-cli -p 端口号 -h 地址 -a 密码
添加服务,开机自启动
# 从解压目录拷贝
cp utils/redis_init_script /etc/rc.d/init.d/redisd
# 编辑脚本文件
vi /etc/rc.d/init.d/redisd
1.添加服务启动参数:# chkconfig: 2345 90 10
意思为redis服务必须在运行级2,3,4,5下被启动或关闭,启动的优先级是90,关闭的优先级是10
2.修改变量对应的路径,${REDISPORT}为端口号
2.修改启动方式为后台执行:$EXEC $CONF &
#!/bin/sh
# chkconfig: 2345 90 10
# Simple Redis init.d script conceived to work on Linux systems
# as it does use of the /proc filesystem.
### BEGIN INIT INFO
# Provides: redis_6379
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Redis data structure server
# Description: Redis data structure server. See https://redis.io
### END INIT INFO
REDISPORT=6379
EXEC=/usr/local/redis/bin/redis-server
CLIEXEC=/usr/local/redis/bin/redis-cli
PIDFILE=/var/run/redis_${REDISPORT}.pid
CONF="/usr/local/redis/${REDISPORT}.conf"
case "$1" in
start)
if [ -f $PIDFILE ]
then
echo "$PIDFILE exists, process is already running or crashed"
else
echo "Starting Redis server..."
$EXEC $CONF &
fi
;;
stop)
if [ ! -f $PIDFILE ]
then
echo "$PIDFILE does not exist, process is not running"
else
PID=$(cat $PIDFILE)
echo "Stopping ..."
$CLIEXEC -p $REDISPORT shutdown
while [ -x /proc/${PID} ]
do
echo "Waiting for Redis to shutdown ..."
sleep 1
done
echo "Redis stopped"
fi
;;
*)
echo "Please use start or stop as first argument"
;;
esac
# 按照脚本文件拷贝一份配置文件,默认端口为6379
cp /usr/local/redis/redis.conf /usr/local/redis/6379.conf
# 注册redisd服务
chkconfig --add redisd
# 查看服务列表
chkconfig --list
# 设置为开机自启动服务
chkconfig redisd on
# 打开服务
service redisd start
# 关闭服务
service redisd stop
添加到环境变量
可以不用到redis程序目录直接执行redis命令
# 修改profile文件
vi /etc/profile
# 在最后行追加
export PATH="$PATH:/usr/local/redis/bin"
# 刷新环境变量
. /etc/profile
三、配置
################################## INCLUDES ###################################
# 指定包含其他的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各实例又拥有自己的特定配置文件
include /path/to/local.conf
################################## MODULES #####################################
# 启动时加载模块。 如果服务器无法加载模块它会中止。 可以使用多个loadmodule指令。
loadmodule /path/to/other_module.so
################################## NETWORK #####################################
# 绑定的主机地址,后跟一个或多个IP地址。如果没有绑定,接受所有IP的连接请求
bind 127.0.0.1
# 保护模式,默认启用。禁止公网访问redis cache,启用有两个条件:没有bind IP,没有设置访问密码
protected-mode yes
# 指定Redis监听端口,默认端口为6379,如果指定0端口,表示Redis不监听TCP连接
port 6379
# 在高并发的环境中,为避免慢客户端的连接问题,需要设置一个高速后台日志
tcp-backlog 511
# redis不监听端口,怎么通信,redis还支持通过unix socket方式来接收请求。可以通过unixsocket配置项来指定unix socket文件的路径,并通过unixsocketperm来指定文件的权限
unixsocket /tmp/redis.sock
unixsocketperm 700
# 当客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
timeout 0
# TCP连接保活策略,单位为秒,向连接空闲的客户端发起一次ACK请求,对于无响应的客户端则会关闭其连接,如果设置为0,则不进行检测。
tcp-keepalive 300
################################# GENERAL #####################################
# 默认不启用,启用守护进程后,Redis会把pid写到一个pidfile中,在/var/run/redis.pid
daemonize no
# If you run Redis from upstart or systemd, Redis can interact with your
# supervision tree. Options:
# supervised no - no supervision interaction
# supervised upstart - signal upstart by putting Redis into SIGSTOP mode
# supervised systemd - signal systemd by writing READY=1 to $NOTIFY_SOCKET
# supervised auto - detect upstart or systemd method based on
# UPSTART_JOB or NOTIFY_SOCKET environment variables
# Note: these supervision methods only signal "process is ready."
# They do not enable continuous liveness pings back to your supervisor.
supervised no
# 指定了pid文件,Redis启动时会将其写入指定的位置并在退出时将其删除。
pidfile /var/run/redis_6379.pid
# 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为notice
loglevel notice
# 日志文件的位置,指定为空字符串为标准输出,如果redis已守护进程模式运行,那么日志将会输出到/dev/null
logfile ""
# 设置为yes会把日志输出到系统日志,默认是no
syslog-enabled no
# 指定syslog的标示符,如果'syslog-enabled'是no,则这个选项无效。
syslog-ident redis
#指定syslog 设备(facility), 必须是USER或者LOCAL0到LOCAL7.
syslog-facility local0
# 设置数据库的数量,默认数据库为0,可以使用select <dbid> 切换数据库,dbid是介于0到‘databases’-1之间的数
databases 16
# 设置为yes来强制执行4.0之前的行为,始终在启动日志中显示ASCII艺术徽标(Logo)。
always-show-logo yes
################################ SNAPSHOTTING ################################
# 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
# 满足以下条件将会同步数据:
# 900秒(15分钟)内有1个更改
# 300秒(5分钟)内有10个更改
# 60秒内有10000个更改
# 可以把所有“save”行注释掉,这样就取消同步操作了
save 900 1
save 300 10
save 60 10000
# 如果用户开启了RDB快照功能,那么在redis持久化数据到磁盘时如果出现失败,默认情况下,redis会停止接受所有的写请求
stop-writes-on-bgsave-error yes
# 指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes
# 在存储快照后,可以让redis使用CRC64算法来进行数据校验,这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能
rdbchecksum yes
# 转储数据库的文件名,默认值为dump.rdb
dbfilename dump.rdb
# 工作目录,指定本地数据库存放目录,文件名由上一个dbfilename配置项指定,这里只能指定一个目录,不能指定文件名
dir ./
################################# REPLICATION #################################
# 主从复制。使用slaveof从Redis服务器复制一个Redis实例。注意,该配置仅限于当前slave有效
# 设置本机为slav服务时,设置master服务的ip地址及端口,在Redis启动时,它会自动从master进行数据同步
slaveof <masterip> <masterport>
# 当master服务设置了密码保护时,slav服务连接master的密码
masterauth <master-password>
# 当从redis与主redis失去了连接,或者正在同步时,redis该如何处理外部发来的访问请求呢
# 第一种选择:yes(默认),从redis仍会继续响应客户端的读写请求
# 第二种选择:no,从redis会对客户端的请求返回“SYNC with master in progress”,也有例外,当客户端发来INFO请求和SLAVEOF请求,从redis还是会进行处理
slave-serve-stale-data yes
# 可以控制从redis是否可以接受写请求。将数据直接写入从redis,一般只适用于那些生命周期非常短的数据,因为在主从同步时,这些临时数据就会被清理掉。自从redis2.6版本之后,默认从redis为只读。
slave-read-only yes
# 只读的从redis并不适合直接暴露给不可信的客户端。为了尽量降低风险,可以使用rename-command指令来将一些可能有破坏力的命令重命名,避免外部直接调用。比如:
rename-command Config za8asd7a8sd7wd87asd9
# 主从数据复制是否使用无硬盘复制功能,新的从站和重连后不能继续备份的从站,需要做所谓的“完全备份”,即将一个RDB文件从主站传送到从站
# 1)硬盘备份:redis主站创建一个新的进程,用于把RDB文件写到硬盘上。过一会儿,其父进程递增地将文件传送给从站。
# 2)无硬盘备份:redis主站创建一个新的进程,子进程直接把RDB文件写到从站的套接字,不需要用到硬盘。
# 在硬盘备份的情况下,主站的子进程生成RDB文件。一旦生成,多个从站可以立即排成队列使用主站的RDB文件。
# 在无硬盘备份的情况下,一次RDB传送开始,新的从站到达后,需要等待现在的传送结束,才能开启新的传送。
# 如果使用无硬盘备份,主站会在开始传送之前等待一段时间(可配置,以秒为单位),希望等待多个子站到达后并行传送。在硬盘低速而网络高速(高带宽)情况下,无硬盘备份更好。
repl-diskless-sync no
# 当启用无硬盘备份,服务器等待一段时间后才会通过套接字向从站传送RDB文件,延迟时间以秒为单位,默认为5秒。设置0秒为关闭,传送会立即启动。一旦传送开始,就不能再为一个新到达的从站服务。从站则要排队等待下一次RDB传送
repl-diskless-sync-delay 5
# 从redis会周期性的向主redis发出PING包,默认是10秒
repl-ping-slave-period 10
# 在主从同步时,可能在这些情况下会有超时发生:
# 以从redis的角度来看,当有大规模IO传输时。
# 以从redis的角度来看,当数据传输或PING时,主redis超时
# 以主redis的角度来看,在回复从redis的PING时,从redis超时
# 用户可以设置上述超时的时限,要确保比repl-ping-slave-period的值要大,否则每次主redis都会认为从redis超时
repl-timeout 60
# 同步之后是否禁用从站上的TCP_NODELAY
# yes会使用较少量的TCP包和带宽向从站发送数据。但这会导致在从站增加一点数据的延时。Linux内核默认配置情况下最多40毫秒的延时
# no从站的数据延时不会那么多,但备份需要的带宽相对较多。默认情况下我们针对低延迟进行优化,但是在非常高的流量条件下,或者当主设备和从设备经过路由转发的次数多时,将其转为yes会更好
repl-disable-tcp-nodelay no
# 设置设置同步队列长度。同步队列是一个缓冲区,当从站断开一段时间,它替从站接收存储数据,当从站重连时,就不必重新全量同步数据,只需要同步这部分增量数据即可
# 只要有一个从站连接,就会立刻分配一个同步队列
repl-backlog-size 1mb
# 如果主redis等了一段时间之后,还是无法连接到从redis,那么缓冲队列中的数据将被清理掉。默认是1个小时,0表示不释放
repl-backlog-ttl 3600
# 给从redis设置优先级,在主redis持续工作不正常的情况,优先级高的从redis将会升级为主redis。编号越小优先级越高,当优先级被设置为0时,这个从redis将永远也不会被选中。默认的优先级为100。
slave-priority 100
# 假如有大于等于3个从redis的连接延迟大于10秒,那么主redis就不再接受外部的写请求。上述两个配置中有一个被置为0,则这个特性将被关闭
min-slaves-to-write 3
min-slaves-max-lag 10
# Redis主站能够以不同方式列出所连接从站的地址和端口
# 从站可以使用以下两个选项,以便向其主站报告一组特定的IP和端口,以便INFO和ROLE都报告这些值。
slave-announce-ip 5.5.5.5
slave-announce-port 1234
################################## SECURITY ###################################
# 设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过auth <password>命令提供密码,默认关闭
requirepass foobared
# 将命令重命名,为了安全考虑,可以将某些重要的、危险的命令重命名。当把某个命令重命名成空字符串的时候就等于取消了这个命令
rename-command CONFIG ""
################################### CLIENTS ####################################
# 设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max Number of clients reached错误信息
maxclients 10000
############################## MEMORY MANAGEMENT ################################
# 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,移除规则可以通过maxmemory-policy来指定,当处理后,仍然到达最大内存,将无法再进行写入操作,但仍然可以进行读取操作
# Redis新的vm机制,会把Key存放内存,Value会存放在swap区
maxmemory <bytes>
# 当内存使用达到最大值时,redis使用的清除策略:
# LRU表示最近最少使用,LFU意味着最少使用
# volatile-lru -> 利用LRU算法移除设置过过期时间的key
# allkeys-lru -> 利用LRU算法移除任何key
# volatile-lfu -> 利用LFU算法移除设置过过期时间的key
# allkeys-lfu -> 利用LFU算法移除任何key
# volatile-random -> 移除设置过过期时间的随机key
# allkeys-random -> 移除随机key
# volatile-ttl -> 移除即将过期的key(minor TTL)
# noeviction -> 不移除任何key,只是返回一个写错误 ,默认选项
maxmemory-policy noeviction
# LRU,LFU和最小TTL算法不是精确的算法,而是近似算法(为了节省内存),默认Redis将检查五个键并选择最近使用的键,可以配置指令更改样本大小获得速度或精度。默认值5会产生足够好的结果,10非常接近真实的LRU但耗CPU,3更快但不是很准确。
maxmemory-samples 5
四、使用
所有key-value都储存在Redis-Object中,Redis-Object主要信息有
- 数据类型(type)
- string (字符串)
- hash (Hash表)
- list (链表)
- set (无序不可重复集合)
- sorted set (有序集合)
- 编码方式(encoding)
- raw
- int
- ht
- zipmap
- linkedlist
- ziplist
- intset
-
数据指针(ptr)
-
虚拟内存(vm)
- …………..
Redis基础命令
# 查看系统信息(Keyspace显示每个键空间中的数据数量)
info
# 测试链接是否OK(PONG为成功)
ping
# 退出客户端
quit
# 持久化到本地
save
# 查看当前键空间中数据量
dbsize
# 切换键空间,默认为0
select 0
# 清除当前键空间数据(info中的Keyspace)
flushdb
# 清除所有键空间数据
flushall
Redis键命令
# 添加字符串类型a-abc
set a abc
# 添加哈希类型a-abc
hset hsah hahaha zhangsan
# 删除a-abc,返回1成功,0失败
del a
# 查看所有key,*为正则表达式,表示所有
keys *
# 判断是否存在,返回1为存在,0为不存在
exists a
# 设置a的生命周期为10秒
expire a 10
# 查看这条数据的生存时间,单位秒,返回-1为不过期,-2表示key不存在
ttl a
# 查看键a对应value的数据类型
type a
# 随机获取key的值
randomkey
# 重命名key,把a命名为b,会覆盖已存在的key
rename a b
# 重命名key,如果b存在会重命名失败
renamenx a b
String操作
# 添加字符串类型a-abc,成功返回OK
set a abc
# 添加字符串类型a-abc,存活时间100秒
setex a 100 abc
# 添加字符串类型a-abc,存活时间10000毫秒(10秒)
psetex a 10000 abc
# 获取指定下表字符串---(abc),闭合空间,包前后边界
getrange a 0 2
# 设置新值,返回旧值---(abc)
getset a zxc
# 设置多个值 a-abc,z-zxc
mset a abc z zxc
# 获取多个值
mget a z
# 添加字符串类型a-abc,键a存在会设置失败
setnx a abc
# 添加字符串类型a-abc,其中一个key存在就会全部设置失败(有原子性)
msetnx a abc z zxc
# 获取字符串长度---(3)
strlen a
# key对应value为数值,value会加一
set s 21
incr s
# key对应value为数值,value会加制定数量
set s 21
incrby s 100
# 同上为减操作
decr
decrby
# 在key对应value的末尾添加字符串,会返回添加后的字符串
append a xyz
Hash操作
# 给key为map的键值设置键为name值为jim
hset map name jim
hset map age 18
# 判断key对应value是否有存在的key,有返回1,无返回0
hexisit map name
# 获取key对应value中的key对应的值,不存在返回nil
hget map name
# 获取key对应value中的所有键值对
hgetall map
# 获取key对应value中的所有key
hkeys map
# 获取key对应value中的所有value
hvals map
# 获取key对应value中的键值对数量
hlen map
# 获取多个
hmget map name age
# 设置多个
hmset map sex nan phone 1234568798
# 删除key对应value中的键值对
hdel map phone sex
# 若map中存在name会添加失败
hsetnx map name newjim
List操作
# 添加list
lpush list 1 2 3 4 5 6 7 8 9 10
# 获取长度
llen lsit
# 按范围取值,栈---("10" "9" " 8")
lrange list 0 2
# 设置指定下表元素 (10->100)
lset list 0 100
# 获取指定下标元素---("5")
lindex list 5
# 移除第一个元素,并返回(100)
lpop list
# 移除最后一个元素,并返回(1)
rpop list
Set操作,Hash实现,复杂度O(1)
# 添加
sadd set a b c d
sadd set a(会失败,set不可重复集合)
# 获取元素数量---(4)
scard set
# 查看所有元素
smembers set
# 获取差集
sadd set1 c d e f
sdiff set set1---("b" "a")
sdiff set1 set---("f" "e")
# 获取交集---("c" "d")
sadd set1 c d e f
sinter set set1
# 获取并集---("d" "f" "b" "a" "c" "e")
sadd set1 c d e f
sunion set set1
# 随机获取指定个数的元素
srandmember set 2
# 判断是否为成员元素,返回1是,返回0不是
sismember set a
# 移除指定成员元素
srem set a b
# 移除一个随机元素并返回该元素
spop set
Sorted Set操作,通过分数保证顺序,Hash实现,复杂度O(1)
# 添加
zadd sortedset 100 a 200 b 300 c
# 元素个数---(3)
zcard sortedset
# 查看元素分数---(100)
zscore sortedset a
# 查看分数区间的元素个数---(2)
zcount sortedset 0 220
# 返回指定元素索引
zrank sortedset a---(0)
zrank sortedset b---(1)
zrank sortedset c---(2)
# 增加元素分数
zincrby sortedset 1000 a
# 按照索引获取元素---("b" "c" "a")
zrange sortedset 0 10
# 按照索引获取元素和分数---("b" 200 "c" 300 "a" 1100)
zrange sortedset 0 10 withscores